Figure 4.2, “Exporting an XTM File with TM4J” shows the interacting objects in the process of exporting a topic map from TM4J. The input to the process is any object which implements the TopicMap interface and the output from the process is an XML file in the XTM 1.0 syntax which represents that topic map.
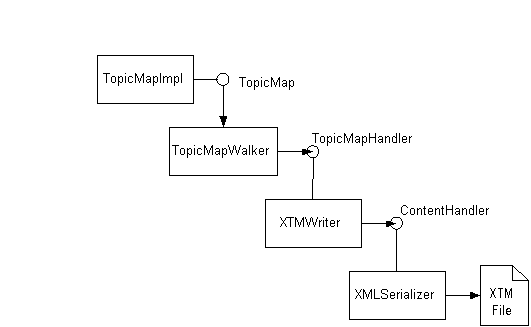
The process of exporting the XTM file is split between three separate, interoperating objects.
- The TopicMapWalker object is responsible for enumerating the objects contained in the topic map being written. Access to the topic map is provided through the TopicMap interface which is implemented by the TopicMapImpl class. It passes the results of the enumeration as topic map object start and end events using the TopicMapHandler interface.
- The XTMWriter object implements the TopicMapHandler interface and translates the start and end of the topic map objects encountered by the walker into XTM syntax and passes them to the ContentHandler interface.
- The XMLSerializer object implements the ContentHandler interface and formats and outputs the text of the XTM file.
Exporting a topic map requires multiple steps in the code. An export function must perform the following steps:
- Create a serialization object. The diagram shows the use of the class org.apache.xml.serialize.XMLSerializer, but any class which implements the org.xml.sax.ContentHandler interface may be used. Depending on the actual implementation used, there may be some steps required to initialize the serializer, such as specifying the output format and the file to be written.
- Create an XTMWriter object. The XTMWriter is connected to the serializer by calling the setContentHandler() method, passing the serializer as a parameter.
- [OPTIONAL] Configure the XTMWriter The XTMWriter supports a set of configuration properties as defined in the table below. To set a property, use the method setProperty(String, String) passing the method name as the first parameter and the property value as the second parameter. The XTMWriter class provides constants for each of the property names which are also listed in the table below.
- Create a TopicMapWalker object.The TopicMapWalker is connected to the XTMWriter by calling the setTopicMapHandler() function, passing the XTMWriter object as a parameter.
- Start the walk.The walk is started by calling the walk() function on the TopicMapWalker, passing the topic map to be saved in as a parameter.
Table 4.2. XTMWriter Configuration Properties
| Property Name | |
|---|---|
| Constant Name | Description |
| http://www.tm4j.org/tm4j/xtmwriter/asfragment | |
| OPTION_WRITE_AS_FRAGMENT | If the value of this property is "true", then the XTM will be written as an XML fragment. This means that no startDocument or endDocument SAX events will be generated. Use this setting to embedd the XTM within the event stream writing a wrapper document. The default value for this property is "false", meaning that startDocument and endDocument events will be generated. |
| http://www.tm4j.org/tm4j/xtmwriter/xtmprefix | |
| OPTION_XTM_PREFIX | The value of this property will be used as the namespace prefix for the XTM namespace in the output XML. The default value for this property is the empty string (""), which results in the XTM namespace being the default namespace for the generated XML elements. |
| http://www.tm4j.org/tm4j/xtmwriter/xlinkprefix | |
| OPTION_XLINK_PREFIX | The value of this property will be used as the namespace prefix for the XLink namespace in the output XML. The default value for this property is "xlink". |
| http://www.tm4j.org/tm4j/xtmwriter/idrefprefix | |
| OPTION_IDREF_PREFIX | The value of this property will be used to prefix IDREF links in the output XML. The default value for this property is "#" and in normal applications should not need changing. |
| http://www.tm4j.org/tm4j/xtmwriter/exportresourceids | |
| OPTION_EXPORT_RESOURCE_IDS | If this option is set to "true" then for each object exported, if that object has a value for its resourceLocator property and if the document part of the resourceLocator matches the document part of the resourceLocator of the containing TopicMap object, then the fragment part of the resourceLocator property of the object will be exported as the id attribute value of the XTM element. If the object being exported is a Topic and its resourceLocator property is not null but the document part of the resourceLocator does not match the document part of the containing TopicMap's resourceLocator, then all of the Topic object's subjectIndicators will be checked and if one of those has a document part which matches the document part of the parent TopicMap's resourceLocator, then the fragment part of that subjectIndicator will be exported as the <topic> element's id attribute. NoteThis setting overrides the exportimpliedids property described below. In other words, if the value of the exportimpliedids property is "false" and the value of the exportresourceids property is "true", then id attributes will still be generated for any object with a non-null value in the resourceLocator property. If both settings are "true", then the ID generated from the resourceLocator of the object takes precedence over the ID generated from the id property of the object. The default value for this property is "true". |
| http://www.tm4j.org/tm4j/xtmwriter/exportimpliedids | |
| OPTION_EXPORT_IMPLIED_IDS | If this property is set to "false", then id attributes will only be generated for <topic> elements. Otherwise, id attributes will be generated for all elements in the exported XTM file which have a value in the sourceLocators property where the document part of the locator matches the document part of the baseLocator property of the TopicMap object. The default value for this property is true. |
| http://www.tm4j.org/tm4j/xtmwriter/writestubtopics | |
| OPTION_WRITE_STUB_TOPICS | If this property is set to "true" then all Topic objects that are not merged and all sets of merged Topics in the TopicMap will be written to the XTM file. If this property is set to "false", then any Topic which only has one sourceLocator and no other properties or one subjectIndicator and no other properties will not be written to the XTM file and wherever that topic is references, a <topicRef> or <subjectIndicatorRef> element will be written using the one existing property. The default value for this property is "true". |
Example 4.3. Exporting a TopicMap
The following source code snippet shows how to export a TopicMap object as XTM syntax XML. This example makes use of the Apache XMLSerializer class which is part of the Xerces XML parser suite. You can find this code in the source file examples/src/examples/ExampleBase.java.
public void writeTopicMap(TopicMap tm, OutputStream os)
{
TopicMapWalker walker = new TopicMapWalker();
XTMWriter writer = new XTMWriter();
OutputFormat of = new OutputFormat();
of.setEncoding("UTF-8");
of.setIndenting(true);
of.setIndent(2);
XMLSerializer serializer = new XMLSerializer(os, of);
walker.setHandler(writer);
writer.setContentHandler(serializer);
try
{
walker.walk(tm);
}
catch(TopicMapProcessingException ex)
{
throw new RuntimeException("Unable to write topic map." , ex);
}
}
}It is possible to filter the output generated by the XTMWriter by inserting a filter class between the walker and the writer objects. A filter must implement the interface org.tm4j.topicmap.utils.WalkerFilter. This interface extends the TopicMapHandler interface and adds a setHandler(TopicMapHandler) method, which can be used to chain another TopicMapHandler instance on to the end of the chain.
In each of the startXXX(), endXXX() or onXXX() methods, the filter can decide whether or not to pass the event on to the chained handler. In addition, returning false from a startXXX() method causes the TopicMapWalker to skip the processing of all children of the object that generated the start event and also to skip the end event for that object - this can be useful in skipping over BaseNames, Occurrences, Associations or whole Topics that you do not want to appear in the XTM output.
There are two useful filters that are part of the org.tm4j.topicmap.utils package. The class org.tm4j.topicmap.utils.InScopeWalkerFilter, can be used to skip any BaseName, Occurrence or Association where the scope does not match a specified set of Topics. You can choose to test that the scope of objects match all of the specified Topics or that the scope of the objects includes at least one of the specified Topics. The class org.tm4j.topicmap.utils.ScopeWalkerFilter provides a little more flexibility to filtering objects by their scope, by allowing you to specify the precise test you want as a uk.co.jezuk.Mango.Predicate. With this filter, for each BaseName, Occurrence and Association, the object is passed to the test(Object) method of the Predicate. If the method returns true, then the object is passed on to the next filter in the chain, otherwise the object is skipped.
Example 4.4. Exporting a TopicMap With A Scope Filter
The following source code snippet shows how to export a TopicMap object as XTM syntax XML while filtering out BaseNames, Occurrences and Associations that do not have a specific Topic in their Scope. This example makes use of the Apache XMLSerializer class which is part of the Xerces XML parser suite.
public void writeTopicMap(TopicMap tm, Topic requiredTheme, OutputStream os)
{
TopicMapWalker walker = new TopicMapWalker();
// Create a filter which requires 'requiredTheme' to be in the
// scope of an object for it to be exported.
InScopeWalkerFilter filter = new InScopeWalkerFilter(
new Topic[] { requiredTheme }, false);
XTMWriter writer = new XTMWriter();
OutputFormat of = new OutputFormat();
of.setEncoding("UTF-8");
of.setIndenting(true);
of.setIndent(2);
XMLSerializer serializer = new XMLSerializer(os, of);
// Chain the walker to the filter
walker.setHandler(filter);
// Chain the writer to the filter
filter.setHandler(writer);
// Chain the serializer to the writer
writer.setContentHandler(serializer);
try
{
walker.walk(tm);
}
catch(TopicMapProcessingException ex)
{
throw new RuntimeException("Unable to write topic map." , ex);
}
}
}